What is artificial general intelligence and what are researchers doing to achieve this goal today? Oriol Vinyals, from Google DeepMind, walks you through the answers to these questions with some interesting examples.
I hope most of you have heard the term of artificial intelligence or artificial general intelligence. The sort of textbook definition would be sort of the study of building agent (as we call them) to solve a a large variety of very complex tasks before without needing to be reprogrammed.
These is a very long quest which we have taken on and there’s still a long way to go for us to sort of see it done. But crucially it’s already shown a lot of advancements and a lot of progress that we already have seen our day today.
But this thought.. I actually want to explain how we the researchers are actually trying to achieve this goal so not only like define it but actually how are we tackling nowadays building agents.
Imagine for a second that I asked you to be sort of a bit of an engineer perhaps and do something that to us looks extremely trivial we do this every day.
“Make a robot open a door”
There’s a robot and I ask you okay you build an algorithm a sequence of instructions to make this robot open the door. It is very common to sort of break out this problem into several pieces and what you could do is sort of say do that right so to open up, find the door, find where the handle of the door, grab it, push it down and open it.
I turns out out that if you actually strictly speaking do this sort of rule-based and hierarchical way to solve a complex problem breaking it down into smaller not so complex problems, you end up with something that perhaps is not so optimal.
Find Door
Find Handle
Grab Handle
Push it down
If you simply try to program, what’s going to happen? If the door is open, (you are not accounting for these) the result is not your fault. The key concept here is that your algorithm will not generalize to the complexity of the world. This by the way is from the darker competition in 2015.
These programs are not really as simple as the four lines I showed you and it really shows that trying to build algorithms to these like rule-based chain of rules (sort of approach) is bound to failure in mistakes. Of course, these were like the funny ones.
Here is how you could do this perhaps in a slightly different way. I call this the learning approach and this is studying a lot knowledge. Take the problem of finding the door. How would you program that? Maybe you have these pixels, you try to find these rectangular objects that look like doors perhaps and as you saw it’s not gonna channel eyes to any conditions you may have not imagined and then you have to try on error iterate and this really doesn’t scale because you’re just now opening doors and how about doing anything else?
The paradigm here is I’m gonna instead try to get a lot of pictures of doors and I have human labelings where the doors are. What I gonna do is I’m gonna learn what a lot door looks like instead of programming in terms of rules. It is very very important.
Unfortunately in computer vision, people care about other objects not doors and people generally don’t take pictures of doors. I am going to show you the example of finding actually cats and dogs which are very popular objects and in the research community. How are we actually gonna do that?

The first step to finding that cat whether an image contains (let’s say a cat or a dog) is to build a big database of pictures that contain either cats or dogs and then literally as humans to label thousands or tens of thousands examples of images like this one which actually is a dog although this one is pretty tricky. I would say so how would you even you know to code these and go through the pictures and so on.
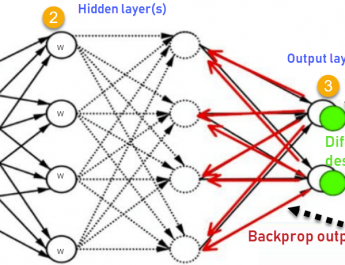
The first piece is to get these databases of labeled examples. Once you have these, the second step is allow for a generic program to be able to learn the characteristics or the patterns on these databases. That’s precisely what deep learning and deep neural nets are enabling us to do.
here you see a big neural network that actually processes the image that were pixels and activates certain neurons in this architecture that could well be for instance detecting the size of the animal, whether it has big ears and so on..
Crucially, these features that these neural network is activating on this image and not prepared by us. These are fully learned from these database. We have the database. We have this model that is powerful enough to represent all sorts of interesting features that eventually lead to an output that is the probability that the image contains cat or dog.
What you essentially do is feed one image at a time to this network of the training database and ask it to predict the correct label all the time. Eventually all these sort of connections settle onto a configuration that works well and generalizes beyond the images that means being trainer and internally so well that in fact the billions of pictures every single day are being analyzed through this kind of algorithm.
![]()
The next and one of the sort of breakthroughs in 2014 which me incorporators and other groups are sort of discovered is not only this idea of taking an image and producing a probability but also taking a sort of sequence of symbols and mapping it through learning examples to another sequence of symbols.
This is a very powerful concept. Because, now we can also learn for instance to do machine translation. So, Here the sequence the input sequence would be the Chinese characters and the output would be English words. Crucially, you learn these without any knowledge of a language or which words correspond to which words. All you need is a large database of pairs of sentences in Chinese and in English translations of each other.
![]()
In fact, Google Translate has been upgraded recently to use these sort of neural networks approaches that essentially reach the gap between the previous best systems and human quality translations by 50% essentially. These again is already used and it’s sort of already out there for everyone to benefit from.

Another such example that is sort of interesting is generating speech. We actually do understand how speech is generated. There is a Google Track which essentially is a bunch of tubes that check changing shape. You could actually model this and this is one of these parametric approaches that you see there on the left. But you can also do is just record this acoustic the audio files essentially from many people which will do very complex from file. There’s like tens of thousands of points per second of speech but again you just let a neural network figure out the sort of patterns in this signal.
What you get end up with is a very good natural-sounding speech system that again beats the gap between the previous best and human speech by about 50% factor. This is some like drastic already sort of well-developed ideas that supervised learning enables us to do and it’s all about this idea of imitation learning. You imitate humans through these powerful models deep neural Nets.
There is another paradigm I wanted to describe which is what if we cannot get a large database of these examples or even better. We want to actually go beyond human capabilities right if we actually want to beat humans. This is the reinforcement learning paradigm and for instance in the game of GO, this was heavily used to for the recent result.
It is extremely simple how this works. It’s almost like obvious. The first step is we have an agent which is in this case the Go player and this agent lives in an environment. The environment would be the Go world. This agent has a goal. For instance, it wants to win at the game of Go and the way this works is quite simple.

The agent observes the environment. When the game finishes and there my environment as won the game or not. After it’s been taught whether or not it updates its ways to ensure that essentially the reward that it gets the probability of winning is maximized.

This agent is very very similar to the neural network that was classifying cat ord dogs. But in this case, it takes as the inputs these observations so it would be a Go board, video games cleaner or not. The outputs are simply the probability of each actions or which judge the position you want to play and through this process you can achieve superhuman performance in playing.
Very crucially, it is most of these algorithms have been developed for games which is kind of funny. Because, as a kid I used to play video games and now I sort of work on making algorithms for video games. I don’t get to play. But despite these profound realizations what you actually get to do when you do through these two video games is being able to scale. Because, as you can imagine this circle of observations and actions initially it’s not very good.
In other words, if you act randomly, you would not gonna get the works very often. So, you have to play a lot in order to achieve good performance. But if you go out to the real world, things will be very slow if you are to build 10,000 robots that you would crash and eventually you learn how to do this that wouldn’t scale very well.
Video games are very important. Because, you can’t run them in parallel in a cluster and if you lose it’s not a big deal. But eventually you are testing sort of ideas about intelligence. Through these video guys which were designed by making essentially humans, imagine and plan and so on. This is our sort of research platform it has been so far until recently. It’s gonna be in the future as well.

But what’s the problem well the environment if the environment is very simple we will learn by simple agents so the environment and the agents go side by side and as you can imagine the is extremely complex. There are like you know predators out there that might want to eat you you need to energy so you might want to eat plants or other other human being not human beings beings and and it’s very diverse and very complex.

It seems like creating environments and creating agents goes both hand by hand and he didn’t need that so one of the the ideas here is if we are simulating the the natural world and we want for instance to get this guy to like survive the winter we we need to simulate snow and food and so on and that is a hard problem by itself as well.
However you know what you can actually try to do is well we researchers not only build agents but we are actually also seeing about the environments that will make agents advance and amongst many new environments that people create last year we created this environment which is called the mine lab which looks like three dimensional you know researchers can set all sorts of tasks to test to test ideas about planning memory imagination and so on.

These environments are becoming more complex and as a result our agents will also of course learn better there.

It is kind of obvious that we need artificial intelligence. It’s very helpful to be able to have translation systems, you might have a personal assistant on your phone like helping you organize streets and so on so forth.
But it also seems that AI needs nature we need to encode these complex rules for AI to be useful to us. Otherwise, we are just bound by the complexity of the environment in which agents live in.

Oriol Vinyals is a Research Scientist at Google DeepMind, working on Deep Learning. Oriol holds a Ph.D. in EECS from University of California, Berkeley, a Masters degree from University of California, San Diego, and a double degree in Mathematics and Telecommunication Engineering from UPC, Barcelona. At Google Brain and Google DeepMind he continues working on his areas of interest, which include artificial intelligence, with particular emphasis on machine learning, language, and vision.
Oriol Vinyals is a Research Scientist at Google DeepMind, working on Deep Learning. Oriol holds a Ph.D. in EECS from University of California, Berkeley, a Masters degree from University of California, San Diego, and a double degree in Mathematics and Telecommunication Engineering from UPC, Barcelona. He is a recipient of the 2011 Microsoft Research PhD Fellowship. He was an early adopter of the new deep learning wave at Berkeley, and in his thesis he focused on non-convex optimization and recurrent neural networks. At Google Brain and Google DeepMind he continues working on his areas of interest, which include artificial intelligence, with particular emphasis on machine learning, language, and vision.